Kali ini saya akan coba membuat tulisan yang bertipe tutorial dan mungkin akan sangat panjang sehingga akan dibagi-bagi dalam beberapa bagian serta sedikit informal. Jadi saya mohon maaf apabila di rangkaian tulisan ini akan kekurangan referensi (tanpa bermaksud untuk tidak hormat kepada orang-orang yang sudah mencetuskan ide-idenya). Namun saya akan mencoba untuk tidak melewatkan referensi mengenai hal yang penting-penting.
Motivasi dalam membuat tulisan ini adalah untuk berbagi ilmu mengenai salah satu paradigma terbaru di dunia machine learning, yaitu Deep Learning, yang diklaim saat ini sebagai model komputasi paling mirip dengan model otak manusia.
Tulisan ini ditujukan kepada pembaca yang sudah cukup familiar dengan salah satu area berikut: artificial intelligence, machine learning (terutama tentang artificial neural network), ataupun computational neuroscience. Namun bagi belum familiar dengan salah satu bidang tersebut atau baru mulai mempelajarinya jangan khawatir, karena saya akan mencoba membahasnya dari dasar sebelum masuk ke pembahasan utama yaitu Deep Learning.
Motivasi lainnya adalah saya ingin menuliskannya dalam bahasa Indonesia agar bisa menjangkau lebih banyak pembaca di Indonesia. Mudah-mudahan suatu saat nanti bisa menjadi karya dalam bentuk buku versi bahasa Indonesia yang bermanfaat.
Sejauh ini saya belum menemukan text book khusus mengenai ini (menurut pencetus metode ini, penyusunan textbook-nya sedang on progress), apalagi dalam bahasa Indonesia. Penjelasan terbaik untuk mulai mempelajari Deep Learning menurut saya bisa mengunjungi situs http://deeplearning.net/.
Berikut materi-materi yang akan dibahas pada rangkaian tulisan ini adalah sbb:
- Pengantar Artificial Intelligence dan Machine Learning
- Contoh Kasus : Regresi Linear
- The Perceptron
- Jaringan Saraf Tiruan (Artificial Neural Network)
- Probabilistic Graphical Model
- Deep Learning
Pada Part 1 ini, kita akan fokus pada poin 1 dan 2.
1. Pengantar Artificial Intelligence dan Machine Learning
Saat ini telah banyak sekali referensi mengenai kecerdasan buatan (artificial intelligence/AI) dan pembelajaran mesin (machine learning) baik berupa buku teks, artikel, maupun berbagai materi online yang bisa diakses secara gratis, karena ilmu AI sudah berkembang kira-kira paling tidak selama 50 tahun terakhir dan machine learning sudah berkembang sejak 20 tahun yang lalu. Berbagai definisi dari sudut pandang berbeda pun telah banyak dirumuskan oleh para pakar. Jadi saya tidak akan detil membahas tentang ini.
Artificial Intelligence
Menurut saya, sederhananya AI adalah ilmu bagaimana membuat atau mendesain mesin/program komputer dapat berperilaku ‘cerdas’ atau berperilaku sebagaimana layaknya manusia. Saat ini sudah tidak sulit untuk menemui produk hasil AI di sekitar kita, mulai dari mesin penjawab pertanyaan, mesin pencari, pengenal suara, pengenal objek, pengemudi mobil otomatis, ‘peramal’ pergerakan saham, hingga robot pembersih rumah. Silakan cari contoh-contoh lain yang ada di sekitar anda :).
Semua produk-produk tersebut biasa disebut sebagai intelligent agent. Walaupun perkembangan intelligent agent dari waktu ke waktu cukup pesat, namun masih jauh dari kecerdasaran manusia. Mungkin intelligent agent ideal yang dapat dihasilkan oleh AI adalah seperti C-3PO droid pada film Star Wars, atau jarvis pada film Iron Man (ada lagi?).
Saat ini telah banyak pendekatan/metode/algoritma yang tersedia sebagai fondasi dari AI, dengan paradigma-paradigma yang berbeda, bahkan untuk beberapa pendekatan bisa sangat berbeda. Fondasi-fondasi tersebut diantaranya algoritma searching, computational logic, neural network, bayesian network, dan evolutionary algorithm. Dikarenakan perbedaan tersebut, jika ada seseorang yang disebut sebagai ilmuwan atau pakar AI, sebenarnya bisa jadi ia merupakan pakar di hanya salah satu metode tersebut.
Machine Learning
Sedangkan, machine learning (sebelum istilah ini muncul, dulu sering disebut sebagai statistical learning) dapat dikatakan sebagai bagian dari ilmu AI.
Salah satu permasalahan dari AI di awal perkembangannya hingga sekarang adalah intelligent agent hanya bisa ‘cerdas’ di lingkungan (ruang dan waktu) tertentu saja. Ketika agent tersebut dipindahkan ke lingkungan yang berbeda, maka agent tersebut mendadak jadi tidak cerdas.
Sebagai ilustrasi, agent yang sudah terprogram sejak awal sebagai robot pembersih rumah akan selamanya menjadi pembersih rumah, atau agent yang sudah terprogram sebagai supir mobil tidak mampu mendadak jadi pengendara motor. Machine learning mencoba menjawab permasalahan bagaimana agent dapat belajar dan beradaptasi dengan perubahan yang terjadi pada lingkungan sekitarnya. Jadi, machine learning merupakan ilmu yang dapat membuat intelligent agent bertambah cerdas atau mampu beradaptasi dengan perubahan lingkungan.
Dari sisi pembuatan intelligent agent, machine learning dapat memudahkan pekerjaan para perancang dan pemrogramnya. Impian para perancang agent adalah dengan cukup satu kali memprogram, si agent mampu mengerjakan apapun. Tidak perlu secara eksplisit mengubah program yang diimplementasi di dalam ‘otak’ agent untuk dapat mengerjakan hal yang belum pernah dilakukan oleh agent tersebut. Selain itu, ada permasalahan yang memang sangat sulit, bahkan tidak mungkin diprogram secara eksplisit (Coba pikirkan bagaimana membuat model matematis/algoritma yang menerima input berupa foto/video lalu dapat mengenali semua objek yang ada di foto tersebut !)
Prinsip dasar Machine Learning adalah learning by experiences. Di kalangan praktisi Machine Learning, experiences seringkali dikenal dengan istilah ‘observed data‘ atau ‘examples‘. Sebagai tambahan, istilah lain dari learning by experiences adalah inductive learning, yang berarti konsep/aturan terbentuk setelah diberikan berbagai macam pengalaman atau contoh-contoh kasus.
Sekadar ilustrasi sederhana mengenai inductive learning, suatu ketika anda bertemu dengan seorang politisi lalu diminta memprediksi apakah ia koruptor atau bukan. Saya pikir akan sulit sekali untuk membuat program corruptor detection secara eksplisit. Terbayang rule-rule yang diperlukan untuk membuat programnya akan sangat rumit. Dengan pendekatan inductive learning, yang anda perlukan adalah data-data historis (dari KPK misalnya) bagaimana ciri-ciri orang yang sudah terdakwa korupsi.
Untuk mempermudah analisis, anda dapat mengidentifikasi terlebih dahulu karakteristik-karakteristik apa saja yang dominan dari seorang koruptor (dalam istilah AI biasa disebut sebagai attributes). Misalnya, attributes dari politisi koruptor tersebut adalah sbb :
- Mendadak kaya,
- Sombong/arogan/angkuh/ria (pokoknya yang sejenis itulah.. ),
- Suka berjanji manis namun palsu,
- Sering gelisah,
- Anggota DPR. (supaya tidak menimbulkan ‘kegaduhan’, saya tegaskan bahwa semua atribut ini hanyalah sekadar contoh, bukan bermaksud untuk menggeneralisasi).
Kemudian, anggaplah anda memakai statistik sederhana sebagai alat untuk melakukan learning (menghitung rata-rata, nilai tengah, modus, simpangan baku, dll, dari masing-masing atribut tsb). Dan ternyata, berdasarkan data dari KPK, anda mendapatkan kesimpulan, misalnya, diatas 75% koruptor memiliki atribut 2) dan 5), atribut2 lainnya di bawah 30%. Kesimpulan yang dihasilkan ini dapat disebut sebagai learned model / rule, dan statistik yang digunakan sebagai alat untuk melakukan analisis disebut sebagai learning system.
Kembali ke permasalahan awal, ketika anda menemui politisi dan diminta untuk memprediksi apakah ia koruptor atau bukan, berdasarkan learning system yang dihasilkan sebelumnya, mungkin pertama kali anda dapat mulai menganalisis apakah ia sombong (atribut 2) dan anggota DPR (atribut 5). Kalau ternyata benar, berarti kemungkinan besar ia koruptor !
Dengan ilustrasi ini, saya sekaligus ingin memperkenalkan lagi istilah lainnya yaitu classification, yaitu memetakan observed data atau atribut-atribut menjadi beberapa classes (kelas). Contoh corruptor prediction ini termasuk permasalahan kategori classification yang memiliki 2 kelas yaitu koruptor dan non-koruptur. Jenis kasus lain yang cukup terkenal adalah regression (regresi), yaitu memetakan data atau atribut-atribut menjadi bilangan real, yang akan coba kita bahas dengan contoh kasus sesaat lagi.
Ada beberapa tipe algoritma machine learning:
- Supervised Learning : Pembelajaran dengan data berlabel, i.e., input data dan target/label diketahui secara jelas
- Unsupervised Learning : Pembelajaran dengan data tidak berlabel, i.e., input data diketahui, namun target/label tidak diketahui. Perancang machine learning biasanya mendefinisikan target tertentu sebagai pendekatan terhadap target sesungguhnya.
- Semi-supervised Learning : Pembelajaran dengan menggabungkan supervised dan unsupervised learning, diakibatkan tidak tersedianya data berlabel yang cukup.
- Reinforcement Learning : Pembelajaran berdasarkan reward dan punishment, juga dikarenakan target/label tidak diketahui.
Ilustrasi corruptor prediction di atas dapat dikategorikan sebagai supervised learning.
2. Contoh kasus : Regresi Linear
Masih ingatkah dengan persamaan garis lurus? masihlah ya 😀 (mungkin sejak SMP kita sudah berkenalan dengan ini). Untuk membuat sebuah garis lurus, kita membutuhkan persamaan :


dimana 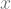


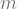

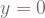
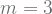
Jika kita memandang persamaan garis ini dari sudut pandang machine learning (dalam hal ini kasus regression), variabel 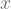



Jika sebelumnya kita dapat menggambar garis dimana persamaan garis dan nilai parameter-parameter telah diketahui, pada regression, kita mencoba untuk menggambar garis yang paling tepat menggambarkan observed data tanpa mengetahui persamaan garis beserta parameter-parameternya. Yang hanya kita ketahui adalah observed data.
Bagaimana persamaan garis yang paling tepat menggambarkan 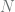
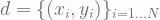
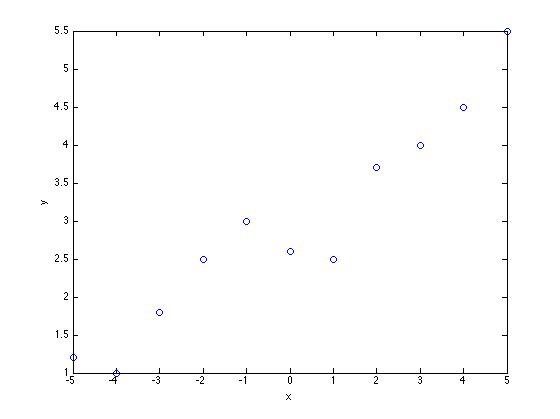
Lebih detilnya, misalnya terdapat 11 sampel observed data
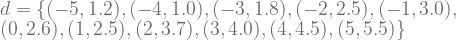
tentukan 



atau
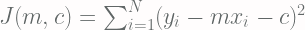
Fungsi 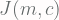
Pertanyaannya adalah bagaimana cara untuk mendapatkan 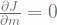
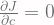

dan
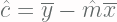
dimana 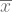

Dengan menggunakan observed data yang sudah diberikan sebelumnya, jika anda menghitung dengan benar, maka anda akan mendapatkan nilai 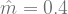
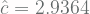
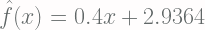
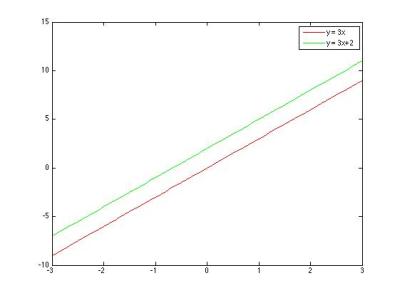
Berikut ini plot dari fungsi linear di atas:

Sekarang cobalah Anda bayangkan sumbu 

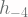
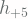

Sudah selesaikah pekerjaan regresi ini? Tentu tidak, karena di lapangan tidak semua kasus dapat disimulasikan dengan persamaan garis lurus (fungsi linear). Malah kebanyakan kejadian yang terjadi di dunia tidaklah linear. Oleh karena itu, kita perlu merumuskan model yang tepat bergantung pada jenis kasusnya (untuk kasus corruptor prediction tadi kira-kira modelnya apa ya yang cocok? :D). Atau lebih canggih lagi, kita merumuskan model yang fleksibel yang dapat beradaptasi sesuai dengan kondisi kasus yang dihadapi (bagi anda yang tertarik, salah satu model regresi ‘canggih’ tersebut adalah Gaussian Process).
Demikian pembahasan di part 1 ini. Masih jauh dari hal mengenai Deep Learning namun sangat berarti untuk dapat memahami metode-metode machine learning yang lebih kompleks. Di bagian berikutnya kita akan membahas sesuatu yang jauh lebih menarik lagi yaitu The Perceptron dan Artificial Neural Network, salah satu learning system sekaligus learned model diadopsi dari sistem jaringan syaraf makhluk hidup yang sejauh ini sangat sukses dalam memodelkan dan memprediksi kejadian non-linear.

kalaw untuk image bisa dibuat dengan menerapakan machine learning??
bisa beri penjelasannya??
Part selanjutnya mana Mas?
Mantap, mudah dipahami bagi saya 😀